Extended Statistics
Extended statistics, which are statistics that can improve cardinality estimates when multiple predicates exist on different columns of a table, or when predicates use expressions.
An extension is either a column group or an expression.
Column group statistics can improve cardinality estimates when multiple columns from the same table occur together in a SQL statement.
Expression statistics improves optimizer estimates when predicates use expressions, for example, built-in or user-defined functions.
Before Columns Group Statistics Let we test advantege of Column group statistics as below. SQL> SELECT COUNT(*) FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57); COUNT(*) ---------- 137 SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57); Explained. SQL> SELECT * FROM DBMS_XPLAN.DISPLAY(); Plan hash value: 2762495579 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 142 | 6958 | 29 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 142 | 6958 | 29 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("EMP_CONTRY"='AFR' AND ("EMP_AGE"=53 OR "EMP_AGE"=57 OR "EMP_AGE"=88)) 14 rows selected. SQL> Post Columns Group Statistics From SYS user SQL> BEGIN DBMS_STATS.SEED_COL_USAGE(null,null,50); END; / PL/SQL procedure successfully completed. SQL> SET LONG 100000 SET LINES 120 SET PAGES 0 SELECT DBMS_STATS.REPORT_COL_USAGE('ABHI_TEST', 'EMPLOYEE_LOCATION') FROM DUAL; SQL> SQL> SQL> 2 LEGEND: ....... EQ : Used in single table EQuality predicate RANGE : Used in single table RANGE predicate LIKE : Used in single table LIKE predicate NULL : Used in single table is (not) NULL predicate EQ_JOIN : Used in EQuality JOIN predicate NONEQ_JOIN : Used in NON EQuality JOIN predicate FILTER : Used in single table FILTER predicate JOIN : Used in JOIN predicate GROUP_BY : Used in GROUP BY expression ............................................................................... ############################################################################### COLUMN USAGE REPORT FOR ABHI_TEST.EMPLOYEE_LOCATION ................................................... 1. EMP_AGE : EQ RANGE 2. EMP_CONTRY : EQ 3. EMP_ID : EQ RANGE 4. (EMP_AGE, EMP_CONTRY) : FILTER ############################################################################### SQL> SELECT DBMS_STATS.CREATE_EXTENDED_STATS('ABHI_TEST', 'EMPLOYEE_LOCATION') FROM DUAL; ############################################################################### EXTENSIONS FOR ABHI_TEST.EMPLOYEE_LOCATION .......................................... 1. (EMP_AGE, EMP_CONTRY) : SYS_STUHXE5IZQ8X5$PUWU38#DZSQT created ############################################################################### SQL> SET LONG 100000 SET LINES 120 SET PAGES 0 SELECT DBMS_STATS.REPORT_COL_USAGE('ABHI_TEST', 'EMPLOYEE_LOCATION') FROM DUAL;SQL> SQL> SQL> 2 LEGEND: ....... EQ : Used in single table EQuality predicate RANGE : Used in single table RANGE predicate LIKE : Used in single table LIKE predicate NULL : Used in single table is (not) NULL predicate EQ_JOIN : Used in EQuality JOIN predicate NONEQ_JOIN : Used in NON EQuality JOIN predicate FILTER : Used in single table FILTER predicate JOIN : Used in JOIN predicate GROUP_BY : Used in GROUP BY expression ............................................................................... ############################################################################### COLUMN USAGE REPORT FOR ABHI_TEST.EMPLOYEE_LOCATION ................................................... 1. EMP_AGE : EQ RANGE 2. EMP_CONTRY : EQ 3. EMP_ID : EQ RANGE 4. SYS_STUHXE5IZQ8X5$PUWU38#DZSQT : EQ 5. (EMP_AGE, EMP_CONTRY) : FILTER ############################################################################### SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57); Explained. SQL> SELECT * FROM DBMS_XPLAN.DISPLAY(); Plan hash value: 2762495579 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 137 | 6850 | 29 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 137 | 6850 | 29 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("EMP_CONTRY"='AFR' AND ("EMP_AGE"=53 OR "EMP_AGE"=57 OR "EMP_AGE"=88)) 14 rows selected. As we can see post Colmn statitics creation Cardinality estimate got corrected and now optimizer know better approach.
1. Column Group Statistics
A column group is a set of columns that is treated as a unit.
Essentially, a column group is a virtual column.
By gathering statistics on a column group, the optimizer can more accurately determine the cardinality estimate when a query groups these columns together.
Why we need Statistics on Column Group
Individual column statistics (like Histogram) are useful for determining the selectivity of a single predicate in a WHERE clause.
When the where clause includes multiple predicates on different columns from the same table,individual column statistics do not show the relationship between the columns.
This is the problem solved by a column group.The optimizer calculates the selectivity of the predicates independently, and then combines them.
However, if a correlation between the individual columns exists, then the optimizer cannot take it into account when determining
a cardinality estimate, which it creates by multiplying the selectivity of each table predicate by the number of rows.
Automatic and Manual Column Group Statistics
Oracle Database can create column group statistics either automatically or manually. And this article is focused only for Manual Method
AUTOMATIC
The optimizer can use SQL plan directives to generate a more optimal plan. If theDBMS_STATSpreferenceAUTO_STAT_EXTENSIONSis set toON(by default it isOFF), then a SQL plan directive can automatically trigger the creation of column group statistics based on usage of predicates in the workload. You can setAUTO_STAT_EXTENSIONSwith theSET_TABLE_PREFS,SET_GLOBAL_PREFS, orSET_SCHEMA_PREFSprocedures. SQL> select DBMS_STATS.GET_PREFS('AUTO_STAT_EXTENSIONS') FROM DUAL; DBMS_STATS.GET_PREFS('AUTO_STAT_EXTENSIONS') -------------------------------------------------------------------------------- OFF
MANUAL
When you want to manage column group statistics manually, then use DBMS_STATS as follows:
User Interface for Column Group Statistics
Several DBMS_STATS program units have preferences that are relevant for column groups.
|
Program Unit or Preference |
Description |
|---|---|
|
SEED_COL_USAGE Procedure |
Iterates over the SQL statements in the specified workload, compiles them, and then seeds column usage information for the columns that appear in these statements. |
|
REPORT_COL_USAGE Function |
Generates a report that lists the columns that were seen in filter predicates, join predicates, and GROUP BY clauses in the workload.You can use this function to review column usage information recorded for a specific table. |
|
CREATE_EXTENDED_STATS Function |
Creates extensions, which are either column groups or expressions. The database gathers statistics for the extension when either a user-generated or automatic statistics gathering job gathers statistics for the table. |
|
AUTO_STAT_EXTENSIONS Preference |
Controls the automatic creation of extensions, including column groups, when optimizer statistics are gathered. Set this preference using SET_TABLE_PREFS, SET_SCHEMA_PREFS, or SET_GLOBAL_PREFS. |
Manual Operations for Column Group Statistics
Below are manual task which is used for managing Column Group Statistics
Detecting Useful Column Groups for a Specific Workload Creating Column Groups Detected During Workload Monitoring. Creating and Gathering Statistics on Column Groups Manually Displaying Column Group Information Dropping a Column Group
1. Detecting Useful Column Groups for a Specific Workload
You can use DBMS_STATS.SEED_COL_USAGE and REPORT_COL_USAGE to determine which column groups are required for a table based on a specified workload.
This technique is useful when you do not know which extended statistics to create. This technique does not work for expression statistics.
Demo of Column Group Statistics
First we will verify if database is able to create SQL PLAN DIRECTIVE.
SQL> select DBMS_STATS.GET_PREFS('AUTO_STAT_EXTENSIONS') FROM DUAL;
DBMS_STATS.GET_PREFS('AUTO_STAT_EXTENSIONS')
--------------------------------------------------------------------------------
OFF
SQL>
SQL> SELECT EMP_CONTRY,COUNT(*) FROM EMPLOYEE_LOCATION GROUP BY EMP_CONTRY;
EMP COUNT(*)
--- ----------
IND 4005
3973
AFR 4020
SQL>
SQL> SELECT COUNT(*) FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57);
COUNT(*)
----------
137
As we can see data is skewed in above table. Let we gather stats and check for HISTOGRAM.
1 SELECT COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
2 FROM USER_TAB_COL_STATISTICS
3 WHERE TABLE_NAME = 'EMPLOYEE_LOCATION'
4* ORDER BY 1
COLUMN_NAME NUM_DISTINCT HISTOGRAM
-------------------- ------------ ---------------
EMP_AGE 78 FREQUENCY
EMP_CONTRY 2 FREQUENCY
EMP_ID 7999 NONE
EMP_POST 11998 NONE
JOIN_DATE 11998 NONE
Now let we query using Where clause with multiple columns.
SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57);
Explained.
SQL> SELECT * FROM DBMS_XPLAN.DISPLAY();
Plan hash value: 2762495579
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 142 | 6958 | 29 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 142 | 6958 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMP_CONTRY"='AFR' AND ("EMP_AGE"=53 OR "EMP_AGE"=57 OR "EMP_AGE"=88))
14 rows selected.
As we can see there are 142 Rows are fetched ,whereas 137 rows should be returned.
As we are working on multi-column in where clause we need to create Extended stats on that.
For creating Extended stats on column we need to tell database to SEED the usage of particular columns.
Now switch to SYS and run below.
SQL> BEGIN
DBMS_STATS.SEED_COL_USAGE(null,null,100);
END;
/ 2 3 4
PL/SQL procedure successfully completed.
Now we are ready to SEED columns. Execute query multiple time as below.
SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57);
Explained.
SQL> SET LONG 100000
SET LINES 120
SET PAGES 0
SELECT DBMS_STATS.REPORT_COL_USAGE('ABHI_TEST', 'EMPLOYEE_LOCATION')
FROM DUAL;
SQL> SQL> SQL> 2 LEGEND:
.......
EQ : Used in single table EQuality predicate
RANGE : Used in single table RANGE predicate
LIKE : Used in single table LIKE predicate
NULL : Used in single table is (not) NULL predicate
EQ_JOIN : Used in EQuality JOIN predicate
NONEQ_JOIN : Used in NON EQuality JOIN predicate
FILTER : Used in single table FILTER predicate
JOIN : Used in JOIN predicate
GROUP_BY : Used in GROUP BY expression
...............................................................................
###############################################################################
COLUMN USAGE REPORT FOR ABHI_TEST.EMPLOYEE_LOCATION
...................................................
1. EMP_AGE : EQ RANGE
2. EMP_CONTRY : EQ
3. EMP_ID : EQ RANGE
4. (EMP_AGE, EMP_CONTRY) : FILTER
###############################################################################
As we can see Column has been successfully Seeded ,Now we are ready to create EXTENDED STATS as below.
2. Creating Column Groups Detected During Workload Monitoring
We will use the DBMS_STATS.CREATE_EXTENDED_STATS function to create column groups that were detected reviously by executing DBMS_STATS.SEED_COL_USAGE.
SQL> SELECT DBMS_STATS.CREATE_EXTENDED_STATS('ABHI_TEST', 'EMPLOYEE_LOCATION') FROM DUAL;
###############################################################################
EXTENSIONS FOR ABHI_TEST.EMPLOYEE_LOCATION
..........................................
1. (EMP_AGE, EMP_CONTRY) : SYS_STUHXE5IZQ8X5$PUWU38#DZSQT created
###############################################################################
As we can see Columns stats has been created with SYSTEM DEFAULT name.
Now let we again gather stats for table as below.
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('ABHI_TEST', 'EMPLOYEE_LOCATION');
PL/SQL procedure successfully completed.
SQL>
Now let we check if Stats are available for extended columns.
SQL> SET LONG 100000
SET LINES 120
SET PAGES 0
SELECT DBMS_STATS.REPORT_COL_USAGE('ABHI_TEST', 'EMPLOYEE_LOCATION')
FROM DUAL;SQL> SQL> SQL> 2
LEGEND:
.......
EQ : Used in single table EQuality predicate
RANGE : Used in single table RANGE predicate
LIKE : Used in single table LIKE predicate
NULL : Used in single table is (not) NULL predicate
EQ_JOIN : Used in EQuality JOIN predicate
NONEQ_JOIN : Used in NON EQuality JOIN predicate
FILTER : Used in single table FILTER predicate
JOIN : Used in JOIN predicate
GROUP_BY : Used in GROUP BY expression
...............................................................................
###############################################################################
COLUMN USAGE REPORT FOR ABHI_TEST.EMPLOYEE_LOCATION
...................................................
1. EMP_AGE : EQ RANGE
2. EMP_CONTRY : EQ
3. EMP_ID : EQ RANGE
4. SYS_STUHXE5IZQ8X5$PUWU38#DZSQT : EQ
5. (EMP_AGE, EMP_CONTRY) : FILTER
###############################################################################
Now we will query again with where clause and multi-column.
As expected 137 Rows are returned now and hence this complete our demo.
SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE EMP_CONTRY='AFR' AND EMP_AGE IN ( 53,88,57);
Explained.
SQL> SELECT * FROM DBMS_XPLAN.DISPLAY();
Plan hash value: 2762495579
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 137 | 6850 | 29 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 137 | 6850 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMP_CONTRY"='AFR' AND ("EMP_AGE"=53 OR "EMP_AGE"=57 OR "EMP_AGE"=88))
14 rows selected.
3. Creating and Gathering Statistics on Column Groups Manually
In some cases, you may know the column group that you want to create. TheMETHOD_OPTargument of theDBMS_STATS.GATHER_TABLE_STATSfunction can create and gather statistics on a column group automatically. You can create a new column group by specifying the group of columns usingFOR COLUMNS. Assumptions This tutorial assumes the following: You want to create a column group for theEMP_CONTRY and EMP_AGEcolumns in theEMPLOYEE_LOCATIONtable inABHI_TESTschema. You want to gather statistics (including histograms) on the entire table and the new column group. Let we first Drop existing Column stats as below. SQL> BEGIN DBMS_STATS.DROP_EXTENDED_STATS( 'ABHI_TEST', 'EMPLOYEE_LOCATION','(EMP_AGE, EMP_CONTRY)' ); END; PL/SQL procedure successfully completed. SQL> Let we verify this. 1 SELECT COLUMN_NAME, NUM_DISTINCT, HISTOGRAM 2 FROM USER_TAB_COL_STATISTICS 3 WHERE TABLE_NAME = 'EMPLOYEE_LOCATION' 4* ORDER BY 1 COLUMN_NAME NUM_DISTINCT HISTOGRAM -------------------- ------------ --------------- EMP_AGE 78 FREQUENCY EMP_CONTRY 2 FREQUENCY EMP_ID 7999 NONE EMP_POST 11998 NONE JOIN_DATE 11998 NONE Let we create EXTENDED STATS manually using DBMS_STATS Packages as below. SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS( 'ABHI_TEST', 'EMPLOYEE_LOCATION', METHOD_OPT => 'FOR ALL COLUMNS SIZE SKEWONLY ' ||'FOR COLUMNS SIZE SKEWONLY (EMP_AGE, EMP_CONTRY)' ); END; / PL/SQL procedure successfully completed. Now let we verify the same as below. SQL> SELECT SYS.DBMS_STATS.SHOW_EXTENDED_STATS_NAME( 'ABHI_TEST', 'EMPLOYEE_LOCATION', '(EMP_AGE, EMP_CONTRY)' ) col_group_name FROM DUAL; SYS_STUHXE5IZQ8X5$PUWU38#DZSQT So extended stats have been created using DBMS_STATS .This is usefull when we know on which column we need to create Extended stats.
4. Displaying Column Group Information
We can use USER_STAT_EXTENSIONS & SYS.DBMS_STATS.SHOW_EXTENDED_STATS_NAME to get details about Extensions.
Now let we verify the same as below.
SQL> SELECT SYS.DBMS_STATS.SHOW_EXTENDED_STATS_NAME( 'ABHI_TEST', 'EMPLOYEE_LOCATION', '(EMP_AGE, EMP_CONTRY)' ) col_group_name FROM DUAL;
SYS_STUHXE5IZQ8X5$PUWU38#DZSQT
Using USER_STAT_EXTENSIONS we can get below details as well
SQL> SELECT * FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='EMPLOYEE_LOCATION';
TABLE_NAME EXTENSION_NAME EXTENSION CREATO DRO
------------------------------ ------------------------------ -------------------------------------------------- ------ ---
EMPLOYEE_LOCATION SYS_STUHXE5IZQ8X5$PUWU38#DZSQT ("EMP_AGE","EMP_CONTRY") USER YES
5. Dropping a Column Group
Use the DBMS_STATS.DROP_EXTENDED_STATS function to delete a column group from a table.
SQL> BEGIN
DBMS_STATS.DROP_EXTENDED_STATS( 'ABHI_TEST', 'EMPLOYEE_LOCATION','(EMP_AGE, EMP_CONTRY)' );
END;
PL/SQL procedure successfully completed.
SQL>
2. Managing Expression Statistics
Till now we have discussed about Column group statistics, now we will look into expression stats.
The type of extended statistics known as expression statistics improve optimizer estimates when a WHERE clause has predicates that use expressions.
About Expression Statistics
For an expression in the form (function(col)=constant) applied to a WHERE clause column, the optimizer does not know how this function affects predicate cardinality unless a function-based index exists.
However, you can gather expression statistics on the expression(function(col) itself.
The following graphic shows the optimizer using statistics to generate a plan for a query that uses a function.
The top shows the optimizer checking statistics for the column.
The bottom shows the optimizer checking statistics corresponding to the expression used in the query.
The expression statistics yield more accurate estimates.
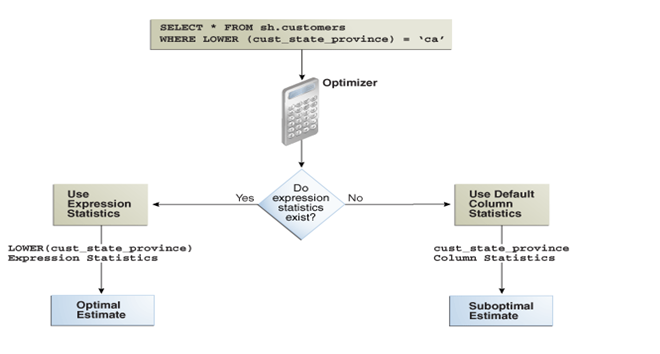
When expression statistics are not available, the optimizer can produce suboptimal plans.
We can perform below task for Expression Statistics.
Creating Expression Statistics
Displaying Expression Statistics
Dropping Expression Statistics
1. Creating Expression Statistics
We can create Expression stats using below 2 methods
GATHER_TABLE_STATS procedureDemonstration
As we can see Total numbers of Rows estimated by Optimizer for AFR expression is 120 where as there are more that that rows exists in table as shared above. As checked there is Column Group Statistics already there, But this is NOT IN USE SQL> SELECT * FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='EMPLOYEE_LOCATION'; TABLE_NAME EXTENSION_NAME EXTENSION CREATO DRO ------------------------------ ------------------------------ -------------------------------------------------- ------ --- EMPLOYEE_LOCATION SYS_STUHXE5IZQ8X5$PUWU38#DZSQT ("EMP_AGE","EMP_CONTRY") USER YES SQL> SQL> select count(*) from EMPLOYEE_LOCATION WHERE UPPER(EMP_CONTRY)='AFR'; COUNT(*) ---------- 4020 SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE UPPER(EMP_CONTRY)='AFR'; Explained. SQL> SQL> SQL> SELECT * FROM DBMS_XPLAN.DISPLAY(); PLAN_TABLE_OUTPUT ------------------------------------------------------- Plan hash value: 2762495579 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 120 | 6000 | 29 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 120 | 6000 | 29 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- PLAN_TABLE_OUTPUT ----------------------------------- 1 - filter(UPPER("EMP_CONTRY")='AFR') 13 rows selected. SQL> Let we create Expression Statistics now. SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS( 'ABHI_TEST', 'EMPLOYEE_LOCATION', method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY ' || 'FOR COLUMNS (UPPER(EMP_CONTRY)) SIZE SKEWONLY' ); END; / PL/SQL procedure successfully completed. Let we check if this is available now. SQL> SELECT * FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='EMPLOYEE_LOCATION'; TABLE_NAME EXTENSION_NAME EXTENSION CREATO DRO ------------------------------ ------------------------------ -------------------------------------------------- ------ --- EMPLOYEE_LOCATION SYS_STU#_7M#H7B0DMOCEOKAMF75W2 (UPPER("EMP_CONTRY")) USER YES EMPLOYEE_LOCATION SYS_STUHXE5IZQ8X5$PUWU38#DZSQT ("EMP_AGE","EMP_CONTRY") USER YES SQL> Now let we Query again our same example with Expression stats. SQL> EXPLAIN PLAN FOR SELECT * FROM EMPLOYEE_LOCATION WHERE UPPER(EMP_CONTRY)='AFR'; Explained. SQL> SELECT * FROM DBMS_XPLAN.DISPLAY(); Plan hash value: 2762495579 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4020 | 211K| 29 (0)| 00:00:01 | |* 1 | TABLE ACCESS FULL| EMPLOYEE_LOCATION | 4020 | 211K| 29 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(UPPER("EMP_CONTRY")='AFR') 13 rows selected. As per above output now Estimated Rows are as per Expected and hence this serve our purpose.
2. Displaying Expression Statistics
To obtain information about expression statistics, use the database view DBA_STAT_EXTENSIONS and the DBMS_STATS.SHOW_EXTENDED_STATS_NAME function.
SQL> SELECT e.EXTENSION expression, t.NUM_DISTINCT, t.HISTOGRAM
FROM USER_STAT_EXTENSIONS e, USER_TAB_COL_STATISTICS t
WHERE e.EXTENSION_NAME=t.COLUMN_NAME
AND e.TABLE_NAME=t.TABLE_NAME
AND t.TABLE_NAME='EMPLOYEE_LOCATION';
(UPPER("EMP_CONTRY")) 2 FREQUENCY
("EMP_AGE","EMP_CONTRY") 234 FREQUENCY
SQL>
SQL> SELECT * FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='EMPLOYEE_LOCATION';
TABLE_NAME EXTENSION_NAME EXTENSION CREATO DRO
------------------------------ ------------------------------ -------------------------------------------------- ------ ---
EMPLOYEE_LOCATION SYS_STU#_7M#H7B0DMOCEOKAMF75W2 (UPPER("EMP_CONTRY")) USER YES
EMPLOYEE_LOCATION SYS_STUHXE5IZQ8X5$PUWU38#DZSQT ("EMP_AGE","EMP_CONTRY") USER YES
3. Dropping Expression Statistics
To delete a column group from a table, use the DBMS_STATS.DROP_EXTENDED_STATS function.
BEGIN
DBMS_STATS.DROP_EXTENDED_STATS('ABHI_TEST', 'EMPLOYEE_LOCATION', '(UPPER(EMP_CONTRY))'
);
END;
PL/SQL procedure successfully completed.
SQL>
SQL>
SQL> SELECT * FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='EMPLOYEE_LOCATION';
EMPLOYEE_LOCATION SYS_STUHXE5IZQ8X5$PUWU38#DZSQT ("EMP_AGE","EMP_CONTRY") USER YES
TABLES & VIEWS & PROC USED
DBMS_STATS.SEED_COL_USAGE
DBMS_STATS.REPORT_COL_USAGE
DBMS_STATS.CREATE_EXTENDED_STATS
DBMS_STATS.AUTO_STAT_EXTENSIONS
DBMS_STATS.DROP_EXTENDED_STATS
DBMS_STATS.GATHER_TABLE_STATS
DBMS_STATS.SHOW_EXTENDED_STATS_NAME
USER_STAT_EXTENSIONS
USER_TAB_COL_STATISTICS
© 2021 Ace2Oracle. All Rights Reserved | Developed By IBOX444